Scalable data caching requires scalable querying – here’s how to achieve it
Modern fintech applications have to process enormous volumes of data. That’s putting new constraints on their performance and scalability.
One of the most crucial tasks of a fintech application is retrieving data quickly for processing. Typically, data sources are slow. One technique to improve performance is in-memory caching of the required data. This means the application can get the data from its own primary memory (RAM), instead of having to make a round trip to a slow data source.
The data requirements of modern applications are complex. Often, applications need to query data using arbitrarily complex conditions. For example, GREATER THAN, LESS THAN, BETWEEN, IN, and so on, combined with multiple AND/OR clauses. Until now, this need has been catered for by the data sources. However, if we use RAM as the source of large volumes of data, we need to query RAM in a similar way. Moreover, as the data cache expands, the querying capabilities on the cache also need to scale.
Cache withdrawal tax
In a naïve implementation, all the cached data objects are iterated and examined against the query filter conditions. The overall time this takes is directly proportional to the number of data objects cached. If the cache holds millions of objects, this approach can be quite slow.
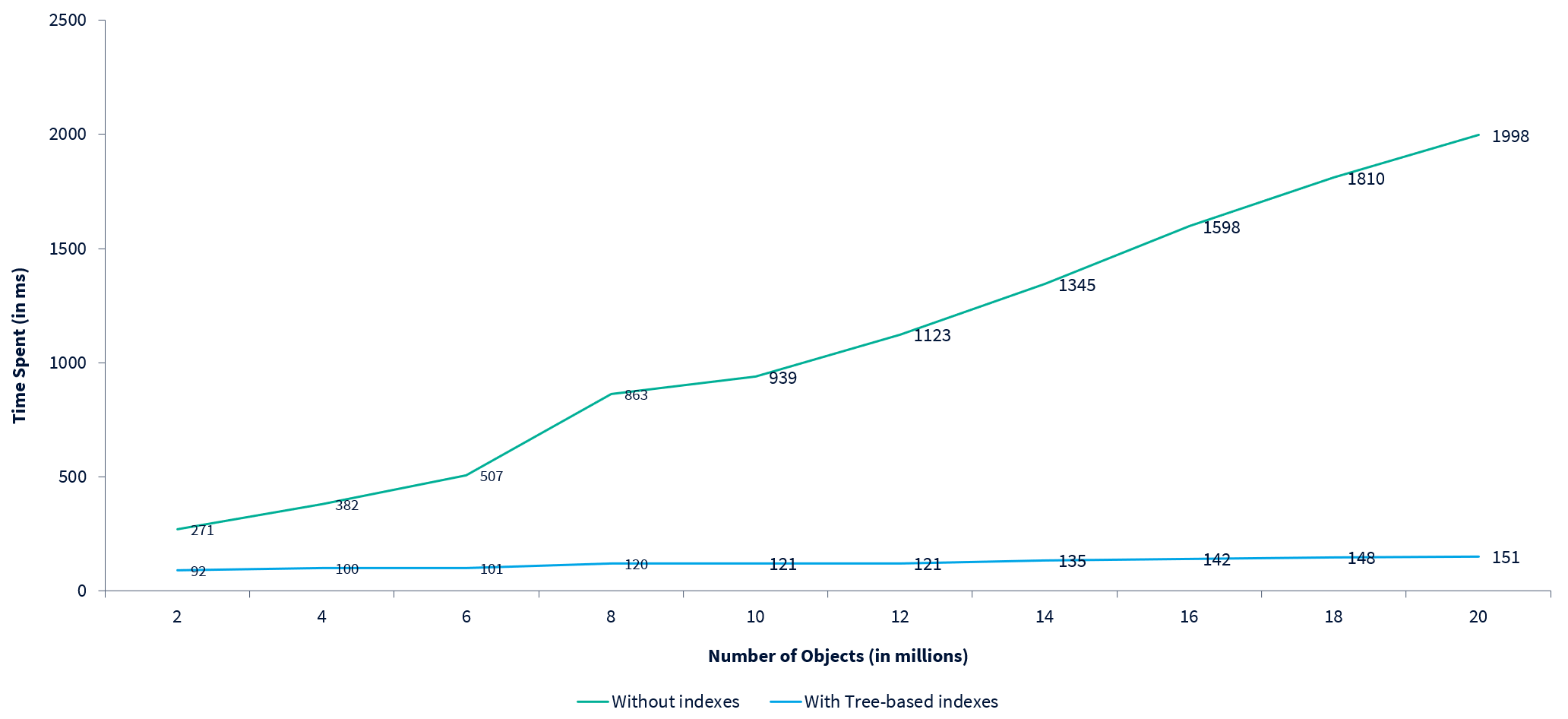
The following chart shows how the time taken increases with the number of objects in an application using the naïve approach:

An old war horse to the rescue
To speed up our cache query, we need to reduce the number of candidate data objects to be scanned. We can do this using a popular technique from the world of databases: indexing.
Indexing is a simple idea. It’s like maintaining the index of a book so that we can go directly to the page we’re interested in. In software terms, we can keep data objects grouped by certain data attributes. If the query contains a filter clause on that attribute, we can directly get the group belonging to that attribute. Then we can filter out the objects returned according to rest of the query conditions. Fewer objects scanned means a faster query.
Six of one, and a half dozen of the other
In a complex application, a cache is often shared by different subsystems. In these scenarios, the query submitted to the cache may not be guaranteed to contain a specific filter clause. To speed up multiple possible queries, we can maintain multiple indexes on the cached set of data objects.
Further, if the structure of the query is not fully controlled (for example, if the query is generated by the application user), it can contain complex conditions connected using multiple ‘AND’ and ‘OR’ clauses. To find the index to be used from such queries, we need to find the largest set of filter clauses that are logically in an ‘AND’ condition with the remaining query filters. We can then safely use one of these filtering attributes to read the corresponding index and apply the rest of the filters on the returned objects. Out of the possible attributes, the one whose index returns the fewest objects can be chosen.
It’s important to note that maintaining multiple indexes increases the overall memory requirement. Also, whenever the cache is updated, all these indexes must be kept in sync. For overall performance and scalability, we have to choose our data structure carefully to ensure it is efficient in these respects.
We can implement an index in different ways, depending on the characteristics of the query filter clauses.
A hash-hash affair
If a filter clause on an attribute is always in the equality form ( = ), we can keep the data objects grouped by that attribute in a hash map. A hash map is highly efficient in retrieving objects that correspond to a given key value.
The overall time this approach takes is independent of the total number of cached objects. Therefore, this approach ensures high performance.
A map hung on a tree
If an attribute can have different conditions in a filter clause, such as GREATER THAN, LESS THAN, and so on, we can keep the grouped data objects in a list, or a binary search tree sorted by the attribute. Any comparison operator on the attribute can be efficiently evaluated on such a data structure to quickly locate the relevant data objects.
With data structures like these, the time taken to locate the grouped objects is usually proportional to the logarithm of the number of possible attribute values. It’s quite fast because the logarithm of even a large number is extremely small.
The following chart shows the time taken by a query filtering an increasing number of data objects. As data volume increases, query time without tree-based indexes increases much faster than query time with them. In-fact, with tree-based indexes the time taken remains relatively constant:
Group some and then group some more
If the cache query generally contains a specific combination of filtering attributes, then data objects can be grouped using the combination as well. In such an index, known as a composite index, objects are grouped using the first attribute. Then the grouped object subsets are further grouped using the second attribute, and so on. This reduces the number of objects to be scanned even further. Any of the data structures we’ve already described can be used to implement a composite index.

ION ARC
ION’s ARC technology powers the data aggregation and reporting capabilities of our products. Thanks to its scalable distributed architecture, ARC can extract, transform, and load huge volumes of data in-memory across several machine nodes. To answer complex data queries quickly, it uses various techniques, including indexing, to filter, aggregate & report the distributed data. We also provide a flexible user interface that allows you to easily design your own interactive reporting dashboards and view this data in various forms.
Learn more about ARC and the applications it powers.

