
Improving transparency in machine learning models for market abuse detection
Key Takeaways
- As ML algorithms become more complex, users demand greater transparency in results
- SHapley Additive exPlanations (SHAP) values provide a standard and clear methodology to address transparency effectively
- SHAP values and visualization tools combined can help interpret classification results
The need for interpretable models
In the previous post, we discussed how the LIST LookOut system tackles alarm classification in market abuse detection (MAD) using machine learning (ML). Now, we turn our attention to the crucial aspect of transparency and interpretability within these tools.
In finance, machine learning offers efficiency in navigating vast datasets and making accurate predictions. However, compliance experts often express concern about the opacity of these models, labeling them “black boxes”. Transparency in ML is not just a preference; it’s a necessity, especially when regulatory compliance is at stake, requiring compliance officers to justify findings to supervisory authorities. Such a necessity is further emphasized by the clear and unambiguous requirements of the market abuse regulation (MAR).
Unveiling the black box: from trees to decisions
In our case, improving model transparency involves understanding the random forest (RF) algorithm. This algorithm consists of decision trees, which, while simple individually, can collectively obscure the rationale behind predictions.
A simplified breakdown of how a random forest (RF) works
- Bootstrap aggregating (bagging): An RF creates multiple subsets of data from the training set with replacement (some data could be repeated).
- Building decision trees: For each subset, a decision tree is constructed. Instead of using all features, the algorithm randomly picks some features for each split. This randomness makes the trees different from each other, making the model more robust towards overfitting.
- Aggregating predictions: For a binary classification problem, each tree predicts an outcome, and the RF combines these predictions into a confidence f(x), which represents a model’s certainty that an instance should be signaled to the regulator as a market abuse alarm. This confidence f(x) can be seen as the ratio of trees voting a class over the total amount of trees in the model.

Understanding the decision-making process of random forests can be challenging due to their ensemble nature, where multiple trees collectively contribute to predictions. Although each tree is independently interpretable, their combined pathways create diversity, making it difficult to track the decision-making process. The algorithm’s random feature selection promotes tree diversity but complicates the understanding of each feature’s impact on the final decision. Additionally, random forests capture complex feature interactions, improving prediction accuracy but making it challenging to articulate input-output relationships. Having analyzed the logic through which the model makes a prediction, the idea is now to define a useful methodology to describe these relationships.
Enhancing model interpretability with SHAP values
SHAP (SHapley Additive exPlanations) values, derived from the Shapley values in cooperative game theory, stand as a transformative solution for unraveling the complexities embodied in ML models. They evaluate how much each feature contributes to a prediction, providing a clear way to see which of them are most influential. This is especially crucial in areas with strict regulations, where explaining how decisions are made is as important as the decisions themselves.
SHAP values work by assigning an “importance value” to each feature for every prediction, clarifying how each piece of data impacts the model’s outcome. This makes the decision-making process transparent and accountable.
Key benefits of SHAP Values
- Consistency: they offer reliable explanations by evenly distributing credit based on each feature’s impact on the prediction.
- Local accuracy: they pinpoint the exact influence of a feature on a specific prediction, ensuring precise explanations.
- Versatility: they can be applied to many types of ML models, making them a versatile tool for improving interpretability.
In short, SHAP values help peel back the layers of ML models, offering insights into how and why these models make their predictions. This not only aids in demystifying complex models but also supports transparency, ensuring they can be trusted and their decisions validated, particularly in regulated environments.
Deciphering SHAP values: a model within a model
SHAP values act as a model within our random forest, serving as an insightful layer and transforming complex interactions between features into a comprehensible narrative of how each of them contributes to predictions. Imagine the RF as the primary model responsible for generating predictions. It considers various features and their interactions to arrive at these predictions. SHAP values act as a secondary model designed to explain the predictions of the RF. They assess the importance of each feature for every prediction, providing insights into how each piece of data influences the model’s outcome.
This approach demystifies the model’s inner workings without diluting its predictive power, adhering to the game theory principle ensuring that every feature is fairly recognized for its unique impact on the outcome.
![]()
This process is akin to creating a separate model that focuses solely on understanding the impact of individual features on the predictions generated by the RF.
In essence, SHAP values serve as a complementary model within our RF model, dedicated to ensuring that predictions are transparent and consistent with the input features.
Employing SHAP values and visualization tools like waterfall plots (which we describe below) sheds light on the nuanced role of features, bridging the gap between the technical intricacies of ML and the imperative for clarity in regulated sectors.
Visualizing model insights: understanding SHAP values and waterfall plots
A waterfall plot (see the graph below) visually complements SHAP values by showing how features collectively influence a model’s prediction. It breaks down each feature’s impact, starting from a baseline value and adding or subtracting contributions along the way. The baseline represents the model’s forecast when none of the features are considered, serving as a reference point. Imagine it as a series of bars, where each bar represents the contribution of a feature. The height of each bar represents the magnitude of the contribution. Positive (light blue) bars increase the prediction relative to the baseline, while negative (dark blue) bars decrease it. For instance, negative bars indicate features reducing the likelihood of the instance belonging to a specific class, while light blue bars suggest the opposite. By plotting the waterfall chart alongside SHAP values, we gain insight into feature interactions and the model’s decision process. This helps interpretability, identifies outliers, detects patterns, and validates model behavior.

Essentially, while SHAP values provide detailed numerical insights, the waterfall plot offers a complementary visual narrative, helping grasp the complex dynamics of the model’s predictions more intuitively.
Real-world applications of SHAP values and waterfall plots
Here we present some examples of classified alarms for the Large Daily Gross pattern, discussed in the previous post of this series. We will explore two cases by using SHAP values and Waterfall plots: a correct (True Positive) and an incorrect (False Negative) classification, as shown in the table below.
| Alarm ID | Predicted classification | True classification | Result |
| 66496208 | To be analyzed | To be analyzed | True positive |
| 66197787 | To be closed | To be analyzed | False negative |
Let’s begin by analyzing the True Positive case for the alarm 66496208. In this case, the classifier correctly says that the alarm has been signaled by the compliance officer. As depicted in the plot below, the majority of features contribute to signaling the alarm. Specifically, features such as “number of involved trades”, “absolute intraday price delta” and “market daily volume” exhibit values pushing towards “signaling”.
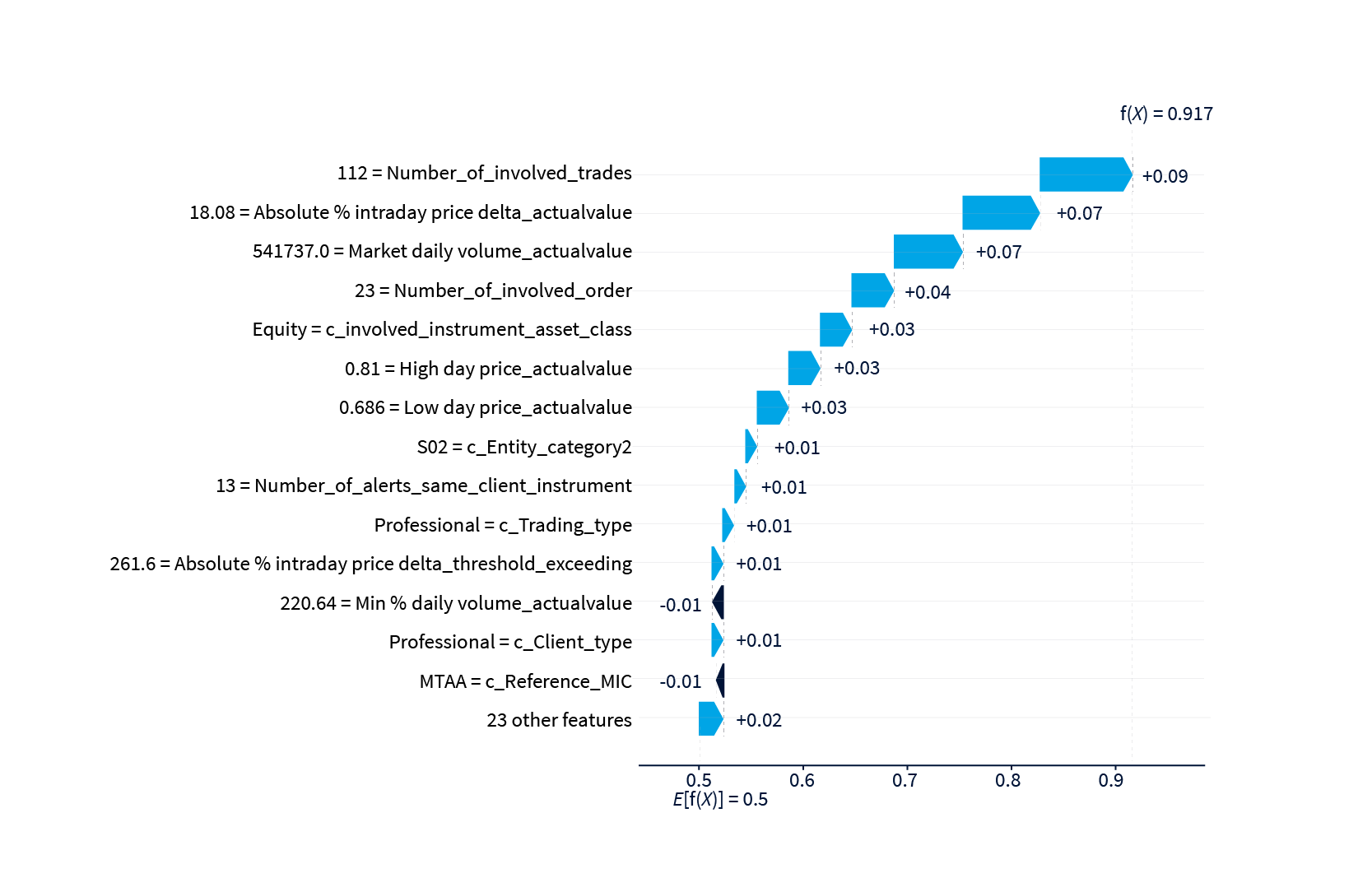
Let’s now look at the False Negative case (alarm 66197787), where the classifier marked the alarm as to be closed, when actually it was signaled. We can see from the plot below that f(x) is close to the signaling threshold of 0.5 and that not all the SHAP values push towards the same direction. Such plot and the related f(x) are crucial to interpret the model result. In this case, for example, a compliance officer looking at this plot could easily realize that the classifier is not providing a clear signal, hence the decision may need further inspection.
![]()
As already discussed, both the waterfall plot and the f(x) value are available within our implementation. This setup aims to equip users with a tool to efficiently identify alarms requiring active review.
Enhancing machine learning transparency
As we deploy ML models for critical tasks like MAD, ensuring transparency and interpretability is crucial. SHAP values emerge as a clear and guiding tool to navigate the intricacies of the model’s predictions, empowering informed decision-making grounded in a thorough understanding of the model’s reasoning. By incorporating SHAP values, we take strides towards bridging the divide between complex ML operations and the need for clear, explainable AI, particularly within the regulated realm of financial compliance.

Don't miss out
Subscribe to our blog to stay up to date on industry trends and technology innovations.


