
DeepMargin: approximating the SPAN 2 algorithm using neural networks
Key Takeaways
- SPAN 2 is more accurate than SPAN but a bigger computational burden
- Its black-box nature and slow margin calculations worry low latency traders
- A neural network outperforms SPAN in approximating SPAN 2 results
An exchange is a regulated market where individuals and companies can trade standardized derivatives defined by the exchange itself. Contracts cannot be set up freely, as in the over-the-counter market.
Exchange markets, such as the Chicago Board of Trade (CBOT), were established to standardize contracts and reduce credit risk. Credit risk occurs when one counterpart defaults and cannot fulfill their obligations. To prevent these scenarios, the exchange interposes itself between the counterparts: when two parties agree to trade a contract, the clearinghouse of the exchange handles the transaction by selling the contract to one trader and buying the contract from the other. This way the credit risk that the two traders face is negligible since the clearinghouse is creditworthy.
The clearinghouse takes on its shoulders all the risks of traders’ defaults, and requires the traders to deposit some security funds, named margin, to protect itself from potential loss. The amount of the margin deposit depends on the trader’s portfolio– it will be high if the portfolio is very risky, and it will be zero if it is riskless. Once the traders meet all the obligations of their contract, they will receive their deposits back.
The clearinghouse updates the client’s portfolio margin daily according to the market’s evolution. If a trader does not meet the updated margin requirements, all the positions in their portfolio will be closed out. The evaluation of an appropriate margin reflecting the risk of a portfolio is crucial for the efficiency of exchange markets. Indeed, few traders would agree to buy or sell contracts if the margin requirements were too high, and the clearinghouse would suffer from credit risk if the margin requirements were too low.
Since 1988, an algorithm developed by the Chicago Mercantile Exchange (CME), named SPAN, has been widely used by several clearinghouses on different exchanges to evaluate margin requirements. SPAN is a scenario-based algorithm, meaning that different future scenarios are taken into account to evaluate a portfolio’s market risk. The margin is then calculated as the difference between the market risk and today’s value of the portfolio. If this difference is negative, the margin will be zero.
In 2023 CME introduced a new algorithm, SPAN 2, initially for energy products, but it will be extended to other products during 2024 and 2025. SPAN 2 uses a far more complex analysis of historical data to assess the risk of a portfolio than SPAN, so the margin evaluation is improved but at the cost of a bigger computational burden. Moreover, SPAN 2’s technical details are not public and the algorithm works as a black-box.
The problem
SPAN 2’s higher computational cost means that it can take up to seconds for a margin evaluation, which could be a problem for traders interested in low latency intraday risk assessments. Moreover, SPAN 2 technical details are not publicly available, so one must rely on the clearinghouse’s API/library to perform the calculation. On the other hand, the SPAN algorithm, despite its lower accuracy, is very fast in margin calculation, and the fact that the algorithm is publicly known makes it replicable and usable by other software as well. For this reason, SPAN is still used as an approximation of SPAN 2 for intraday calculations.
To address the computational time required to evaluate a portfolio’s margin, we propose a neural network approximation to the SPAN 2 algorithm.
Our approach
We have used the following supervised machine-learning procedure:
- At the market closure we generate a great number of random portfolios;
- We evaluate all the portfolios margins using both SPAN 2 and SPAN algorithms;
- We train the network using as input the portfolios and as output the percentage difference between the two algorithms;
- We use the trained network and the SPAN margin to evaluate an approximation of SPAN 2 margin.
The network input
The input data is composed of portfolios. A portfolio is a collection of instruments, each with distinctive features, including the instrument type, the price, the quantity, the underlying, the expiry date and strike for the option. We can represent each portfolio as a table, like this:
| Type | Price | Quantity | Underlying | Expiry | Strike |
| Long Future | 0$ | 10 | Crude Oil | 03/22/24 | – |
| Long Call European | 30$ | 40 | Crude Oil | 02/23/24 | 100$ |
| Short Call American | 20$ | 60 | Pork Belly | 06/16/24 | 80$ |
From this example, it is evident that the portfolios, in addition to each having different lengths, are composed of both numerical and categorical features. This prompted us to tackle the problem using a Small Language Model approach, similar to the one used in generative AI.
The network output
The network is trained to adjust the SPAN margin instead of directly predicting the SPAN 2 one. This approach leverages the information retained in the SPAN margin and the network can learn just the relative error δ, such that:
SPAN2 = (1+δ) × SPAN
The results
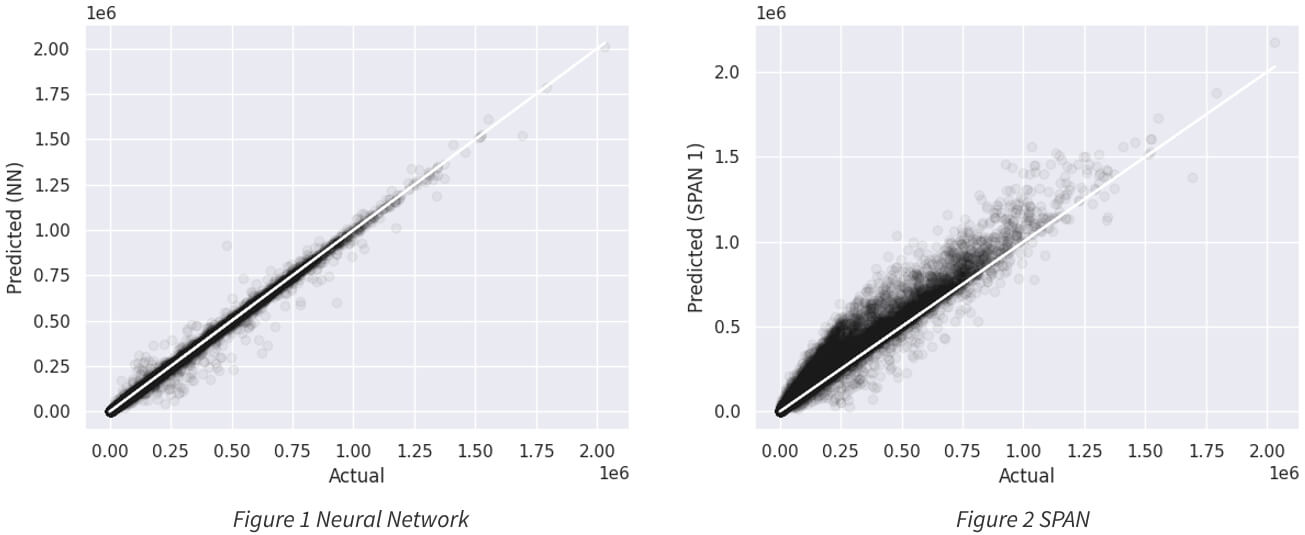
We remark that many traders rely on the SPAN algorithm as a fast approximation of the SPAN 2 margin. Hence the neural network must be more accurate than SPAN to be useful in practical applications. Starting from the dataset of randomly generated portfolios, we extracted 10,000 portfolios to use as a test set, on which the network has not been trained. After training, we test the neural network on these 10,000 portfolios. The results have been plotted in the scatter plot below, in Figure 1 and Figure 2, where on the x-axis there is the actual value of SPAN 2 margin and on the y-axis the predicted value, from the neural network on the left and from the SPAN algorithm on the right. The closer the points are distributed to the bisector of the quadrant, the better the prediction algorithm is, so it is clear that the neural network is better than the SPAN.
We also tested the network to assess the accuracy of the model by using the Median Absolute Error (MAE) between the model (neural network or SPAN) and the SPAN 2 margin. The resulting error distribution is shown in Figure 3. We can observe that the improvement was approximately by a factor of eight moving from an MAE of 1136.42 for SPAN to an MAE of 140.51 for the neural network.
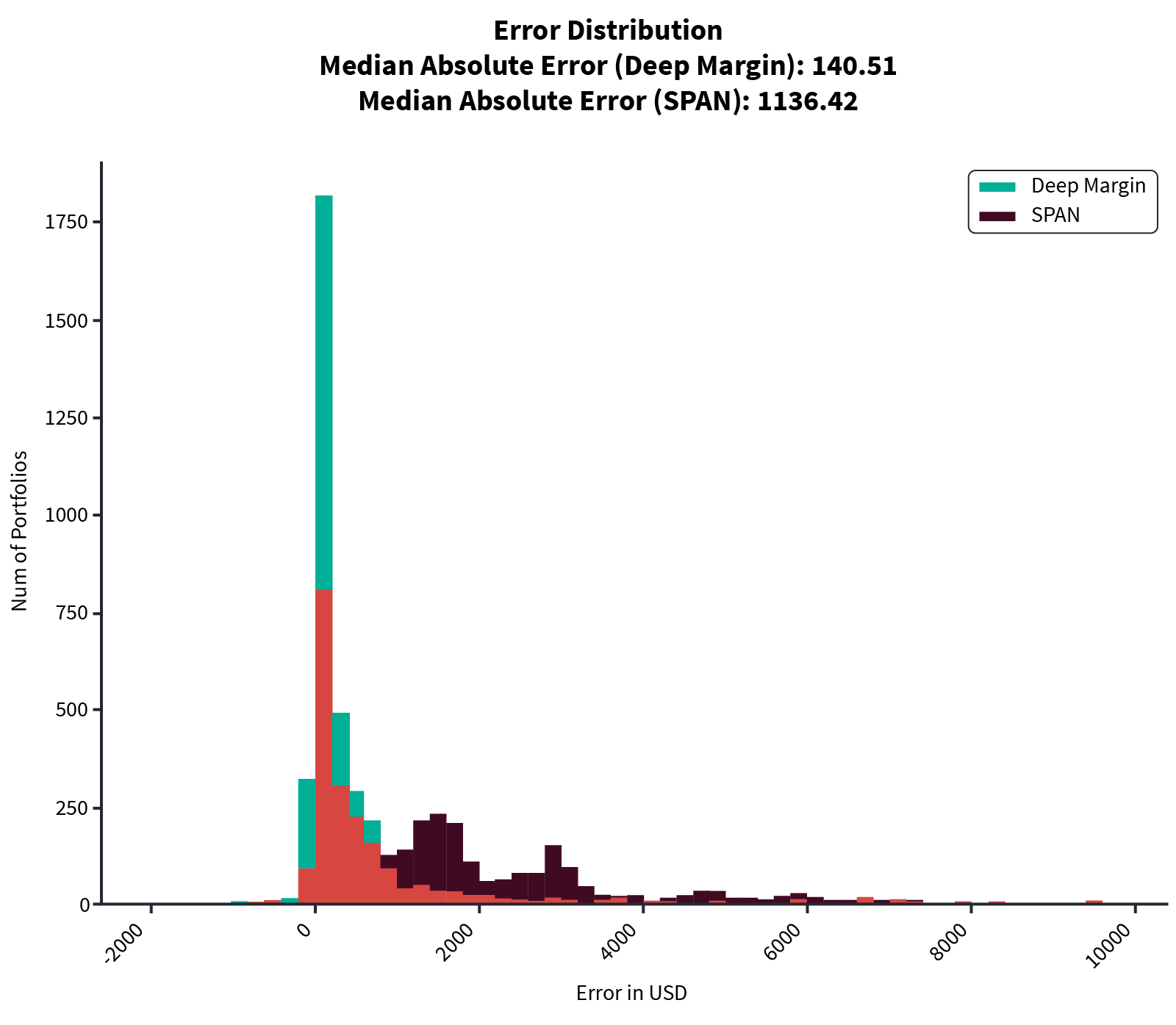 Error Distribution (Median Absolute Error)
Error Distribution (Median Absolute Error)As we have seen, by using a neural network we have obtained a better approximation of SPAN 2 than SPAN. Indeed, the neural network calculation has a median average error almost eight times smaller than SPAN, and a much narrower error distribution. Moreover, the computation time has been reduced from a few seconds using SPAN 2 library to a few milliseconds using the neural network.

Don't miss out
Subscribe to our blog to stay up to date on industry trends and technology innovations.